Migrate a CloudKarafka Apache Kafka® cluster to Aiven with MirrorMaker 2
Learn how to migrate a CloudKarafka Apache Kafka® cluster to Aiven for Apache Kafka® using Apache Kafka® MirrorMaker 2.
What you will learn
This tutorial teaches you how to migrate from an instance of CloudKarafka Apache Kafka® to an Aiven for Apache Kafka® instance.
If you are migrating an Apache Kafka® cluster from another provider, see the generic tutorial.
This tutorial covers:
- Prerequisites: what should you pay attention to before migrating?
- Syncing data with Apache Kafka MirrorMaker 2
- Migrating Apache Kafka topic schemas
- Migrating Apache Kafka ACLs (Access Control Lists)
- Migrating Apache Kafka consumer group offsets
- Migrating Apache Kafka clients and connectors
What are you going to build
This tutorial outlines all common the steps to migrate an existing Apache Kafka® cluster to a new service provider using MirrorMaker 2.
All migrations are different, so this is a general rather than specific guide. This tutorial outlines a set of checks, actions and processes to follow to perform a complete migration.
We'll use MirrorMaker 2 to migrate the data. MirrorMaker 2 is a fully managed distributed Apache Kafka® data replication utility.
Warning
MirrorMaker 2 provides asynchronous replication across clusters. To avoid data loss during the migration, you need to ensure that the replication lag is 0 before pointing the new producers and consumers to the target Kafka environment. More information in the monitor the MirrorMaker 2 replication flow lag section.Prerequisites
This tutorial assumes you have both:
- a CloudKarafka Apache Kafka® cluster at a Dedicated service level or above.
- Aiven does not have equivalents for CloudKarafka's shared tenancy (developer) service levels. Before beginning, you must upgrade your cluster to any Dedicated service level.
- an Aiven account. Sign up for Aiven if needed.
The exact migration steps vary depending on the existing source Kafka system. This tutorial focuses on migrating the Apache Kafka topics to Aiven.
Note connection details in CloudKarafka
Log into the CloudKarafka console and note the following - we'll need this information for the migration.
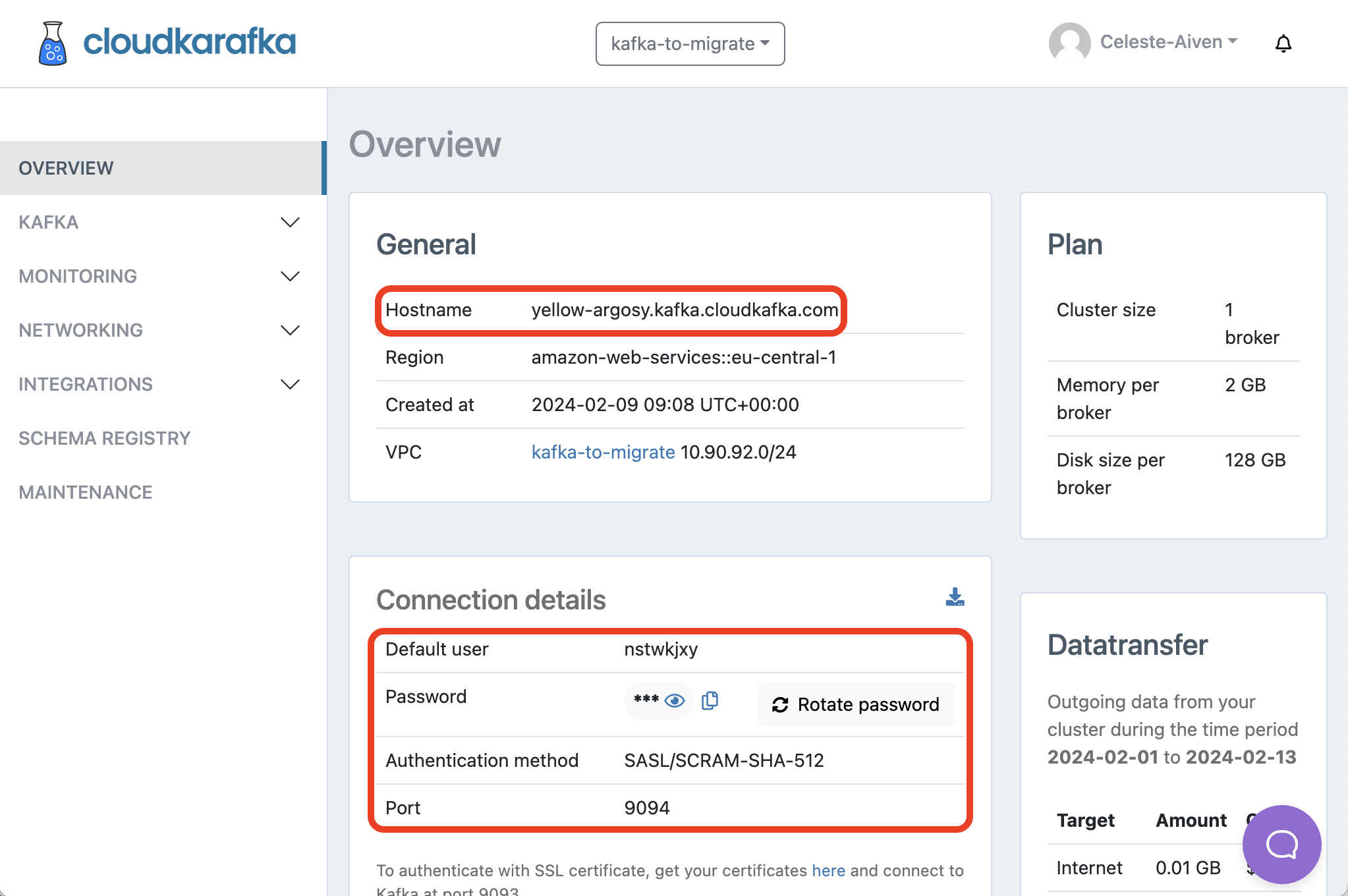
From the Service Overview page:
- The Hostname
- The Default user, Password, Port and Authentication method
From the Cluster page:
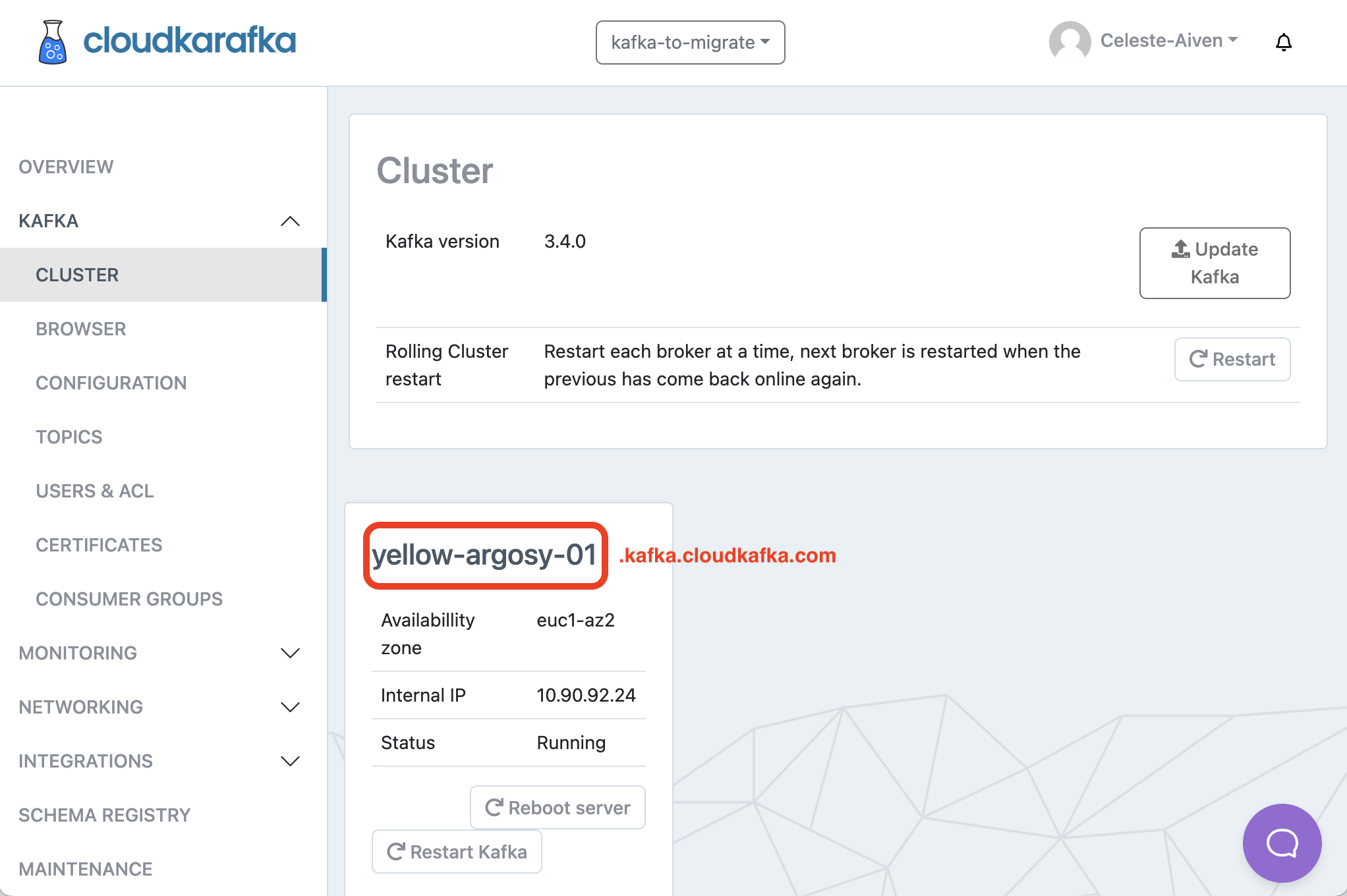
- The Server details for each server listed, in the format
servername.kafka.cloudkafka.com. These will form the basis of the bootstrap servers we use in subsequent steps.
Optional: create a test topic and stream data to it
If you are migrating a production Kafka cluster, it might be useful to create a test topic with data in it to migrate first, before working with live data.
You can use Aiven's Fake Data Producer to do this.
In your CloudKarafka Kafka cluster, create a topic called pizza-orders. Then, use data faker the SASL_SSL security protocol option, omitting the kafkaCerts folder to stream data to it:
python main.py \ --security-protocol SASL_SSL \ --sasl-mechanism SCRAM-SHA-256 \ --username <CLOUDKARAFKA_USERNAME> \ --password <CLOUDKARAFKA_PASSWORD> \ --host <CLOUDKARAFKA_SERVER> \ --port <CLOUDKARAFKA_PORT> \ --topic-name pizza-orders \ --nr-messages 0 \ --max-waiting-time 0 \ --subject pizza
Where:
<CLOUDKARAFKA_USERNAME>is the CloudKarafka Deault user<CLOUDKARAFKA_PASSWORD>is the password of that default user<CLOUDKARAFKA_SERVER>is the CloudKarafka Hostname<CLOUDKARAFKA_PORT>is the CloudKarafka Port
Remember to stop the data faker when you aren't actively using it!
Create an integration endpoint in Aiven
The first step you'll need to perform in the Apache Kafka migration is identifying the source Kafka cluster where the data is migrated from and create a connection to it.
If you're using Aiven for Apache Kafka, you need to define the source Kafka cluster as External Integration following the steps below:
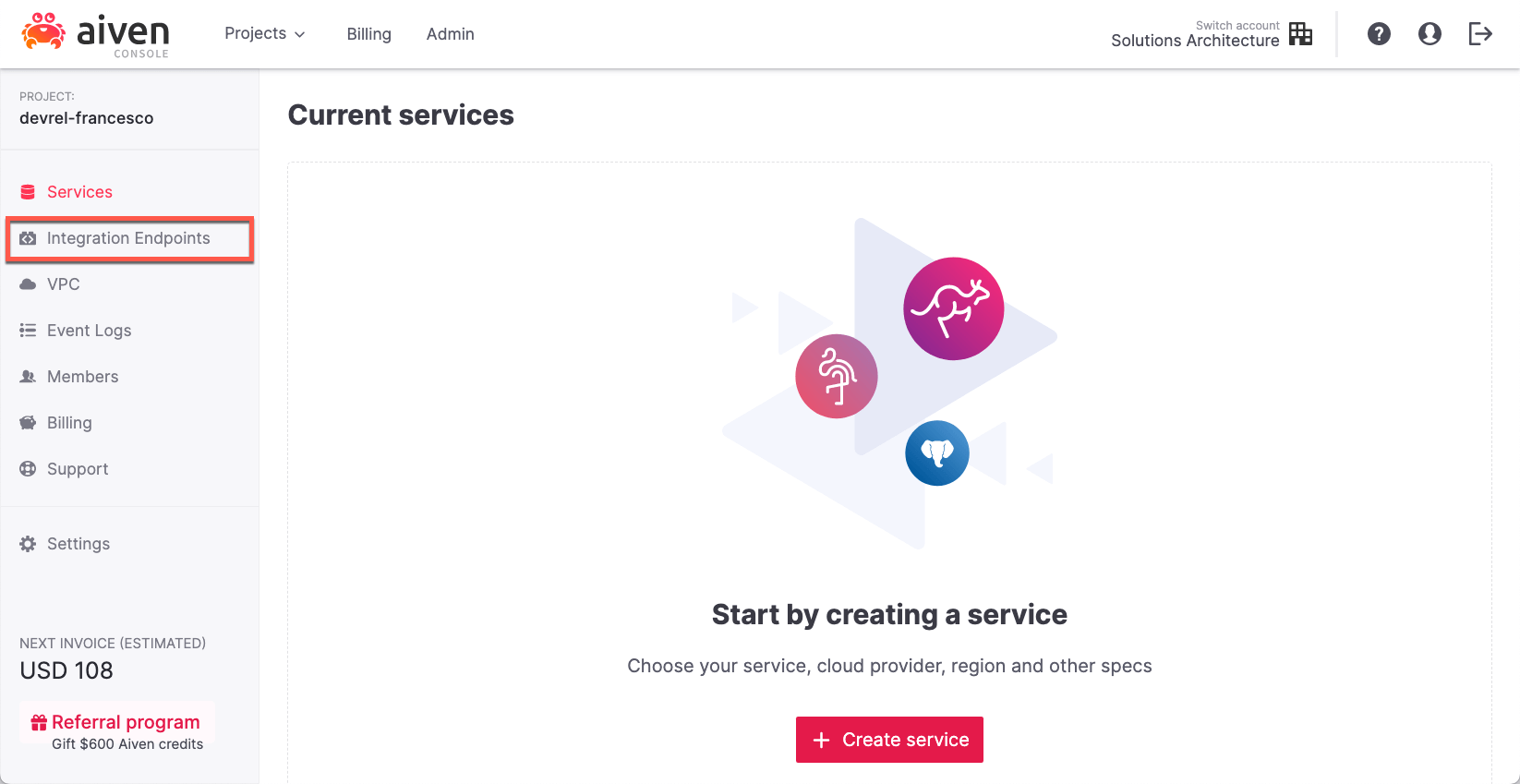
-
Go to the Aiven Console.
-
Click on Integration Endpoints.
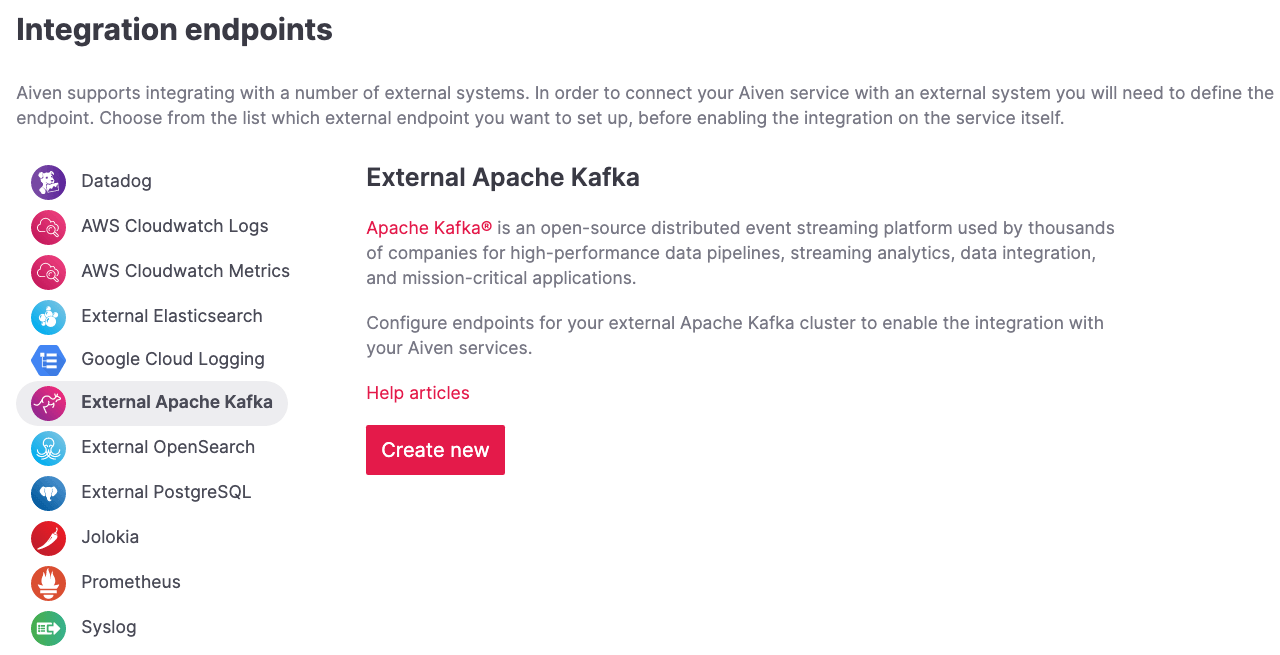
-
Select External Apache Kafka and click on Create New.
-
Give the endpoint a name (like
source-cluster), this will later be used as reference by MirrorMaker 2. -
Add the following parameters:
- Name: The name of the endpoint, for example
source-cluster. - Bootstrap servers: The CloudKarakfa Hostname and and Port listed in the format:
<server-details>.kafka.cloudkafka.com:<port>. - Security Protocol: SASL_SSL
- Username: The CloudKarafka user name
- Password: The CloudKarafka password
- SASL Mechanism: SCRAM-SHA-512
- Name: The name of the endpoint, for example
Click Save.
Create the target Kafka cluster and MirrorMaker 2 instance
Next, create the Apache Kafka cluster to migrate to, and the MirrorMaker 2 instance we'll use to sync the two clusters.
We'll create these services in Aiven for the purposes of this tutorial.
In the Aiven Console, create:
- An Aiven for Apache Kafka service named
target-kafkafor data streaming. This is the target Kafka cluster for the migration. - An Aiven for Apache Kafka MirrorMaker 2 service named
mm2, MirrorMaker 2 will be used to stream the data from the source Apache Kafka cluster totarget-kafka.
Create an Aiven for Apache Kafka® service
The Aiven for Apache Kafka service is the target cluster for the migration. You can create the service with the following steps:
-
Log in to the Aiven web console.
-
On the Services page, click Create a new service.
This opens a new page with the available service options.

-
Select Apache Kafka®.
-
Select the cloud provider and region that you want to run your service on.
-
Select
business-4as service plan. -
Enter
target-kafkaas name for your service. -
Click Create Service under the summary on the right side of the console.
Customize the Aiven for Apache Kafka service
Now that you've created your target cluster, you need to customize it's functionality. In the Overview tab of your freshly created service, you'll see a bunch of toggles and properties. Change these three:
-
Enable REST APIs: via Kafka REST API (Karapace) > Enable.
Note
The Kafka REST API allows you to manage and query Apache Kafka via REST APIs. You'll use it to inspect the data in Apache Kafka from the Aiven Console. -
Auto creation of topics: via Advanced configuration > Add configuration option >
kafka.auto_create_topics_enable, switch the setting on and then click Save advanced configuration.Note
Thekafka.auto_create_topics_enablesetting allows you to create new Apache Kafka® topics on the fly while pushing a first record. It avoids needing to create a topic in advance. To read more about the setting, check the dedicated documentation. -
Enable SASL : Enable SASL via the dedicated configuration option.
- After doing this, in the Overview, toggle the authentication type to SASL as well
Create an Aiven for Apache Kafka MirrorMaker 2 service
The Aiven for Apache Kafka MirrorMaker 2 service syncs the data between the source and target clusters in the migration. You can create the service with the following steps:
-
Log in to the Aiven Console.
-
Click on the Aiven for Apache Kafka service you created previously, named
target-kafka. -
On the Overview tab, scroll down until you locate the Service integration section and click on Manage integrations.

-
Select Apache Kafka MirrorMaker 2.
-
In the new window popup, select the New Service option and click on Continue.
-
Give the new service a name,
mm2, then select the cloud provider, region, and service plan. Then click on Continue. -
Define the Cluster alias, this is the logical name you'll use to define the target
target-kafkacluster. Usekafka-target.
Once you follow all the steps, you should see an active integration between target-kafka and mm2 named kafka-target:

Create a data replication using MirrorMaker 2
The next step in the migration journey is to create a data replication from the source cluster to the Aiven for Apache Kafka service named target-kafka. To create a replication you need to:
- Create an alias for the source Apache Kafka cluster (the target alias
kafka-target). - Define the replication flow.
Create an alias for the source Apache Kafka cluster
To create a MirrorMaker 2 replication flow, first create an alias to point to the source Kafka cluster. You defined the target alias kafka-target during the creation of the MirrorMaker 2 service, so use that.
To create the alias with the Aiven Console you can follow the steps below:
-
Navigate to the MirrorMaker 2
mm2service page. -
Click on the Integration tab.
-
Scroll until you reach the External integrations section.
-
Select Cluster for replication within the available external integrations.
-
Select the endpoint name you defined in a previous step (
source-cluster) and click Continue.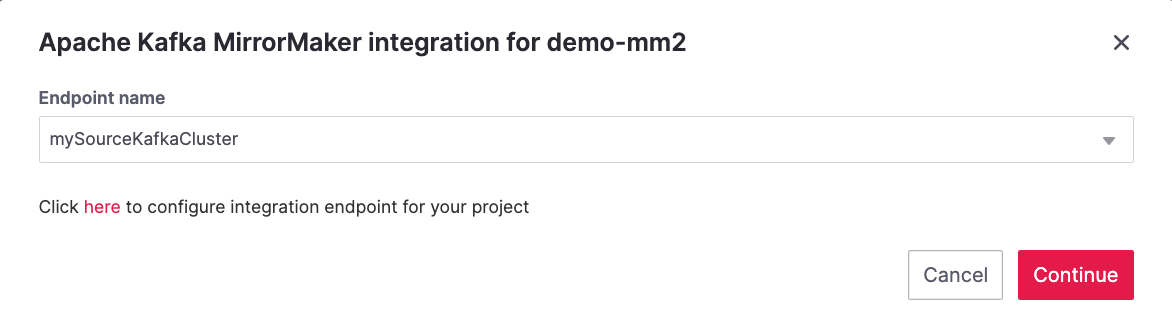
-
Give the source cluster an alias name, for example
kafka-source, and click Enable.
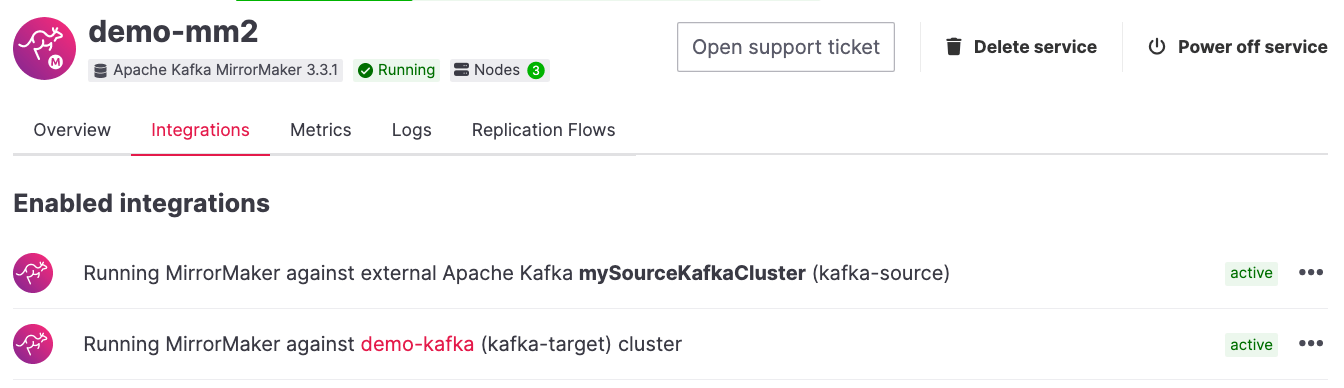
Once the steps are done, you should be able to see the two aliases, kafka-source and kafka-target defined as integrations in the demo-mm2 service:
Warning
If you experience connection problems to the source or target clusters, the MirrorMaker 2 service overview page shows the following error: . You can also review the service logs by clicking on the Log tab.
. You can also review the service logs by clicking on the Log tab.Start the MirrorMaker 2 replication flow
Warning
If your topic requires certain configurations such as compaction or specific partitioning configurations, we recommend creating your topic in Aiven for Apache Kafka before starting the replication flow. MirrorMaker 2 will not recreate topics with the same configuration options as the source Kafka cluster.In the previous steps you defined MirrorMaker 2 source and target aliases. Now it's time to define the replication flow.
You first need to identify the set of topics you want to migrate to the new cluster, and create a Java regular expression that includes them.
For example, if you want to migrate all the topics starting with customer. and the ones containing .logistic. you can add the two regular expressions: customer\..* and .*\.logistic\..*.
To migrate all topics, Use .*.
Tip
You can list both topics to be included and excluded in the allow list and stop list.Next, create a MirrorMaker 2 replication flow in the Aiven Console:
-
Navigate to the
demo-mm2service page. -
Click on the Replication Flows tab.
-
Click on Create replication flow.
-
Fill in the replication flow details:
-
Source cluster:
kafka-source- the alias defined for the source Kafka cluster. -
Target cluster:
kafka-target- the alias defined for the target Aiven for Apache Kafka cluster. -
Topics: the Java regular expression defining which topics to include.
For instance
customer\..*to include all topics starting withcustomer..*\..europe\..*to include all topics including with.europe..
-
Topics blacklist: the Java regular expression defining which topics to exclude. E.g.
*\..testto exclude all topics ending withtest.. -
Sync group offset: to define whether to sync the topic containing the consumer group offset.
-
Sync interval in seconds: to define the frequency of the sync.
-
Offset syncs topic location: to provide offset translation, MirrorMaker 2 uses the
mm2-offset-syncstopic. To ensure we don't lose any data, set this to target. -
Replication policy class: controls the prefix when replicating topics.
DefaultReplicationPolicysets the topic name in the target Kafka service assource_cluster_alias.topic_name(prefixing the topic name with the source cluster alias), whileIdentityReplicationPolicysets the target topic name equal to the source topic name. -
Emit heartbeats enabled: allow MirrorMaker 2 to emit heartbeats to keep the connection open even in cases where no messages are replicated.
-
Enable: to enable the data sync job.
The following represents an example of a replication flow setting:
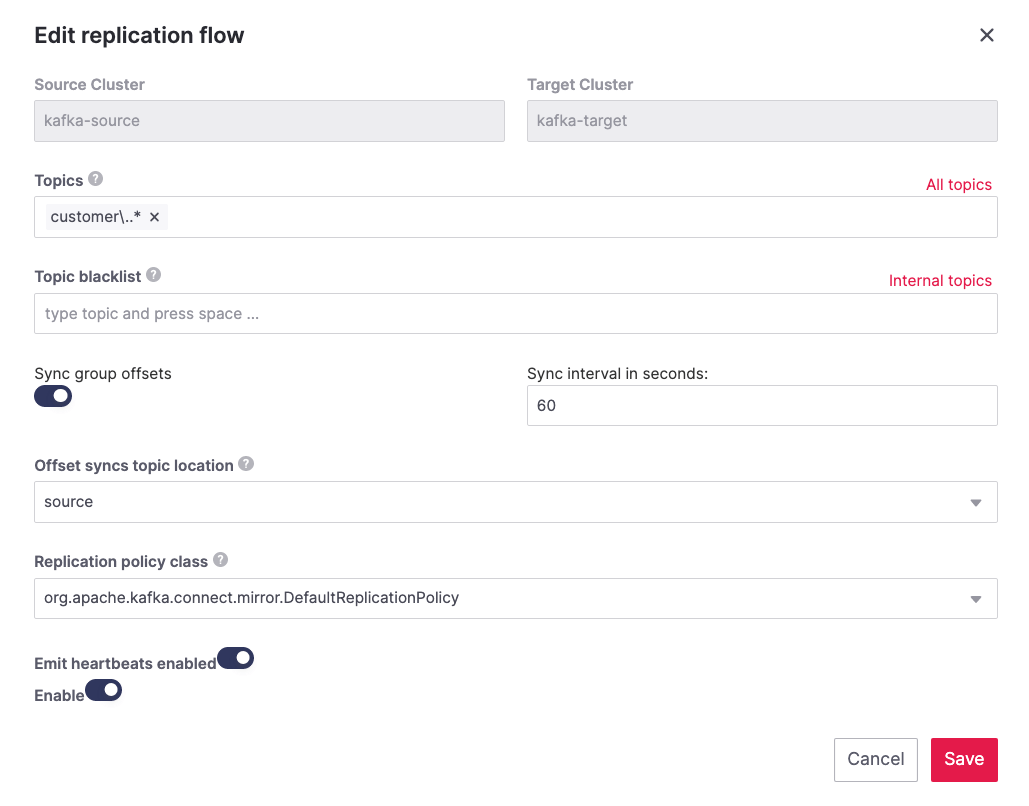
-
-
Click on Create
After following the steps above, you should see the enabled replication flow:
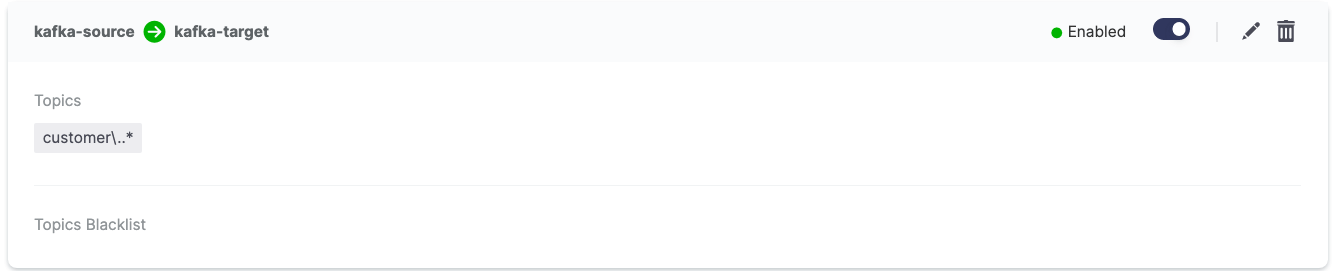
Browsing the target target-kafka service, you should see the topics being replicated. The following image shows replication (using the DefaultReplicationPolicy) of the kafka-source.customer.clicks and kafka-source.customer.purchases topics together with MirrorMakers 2 internal topics.
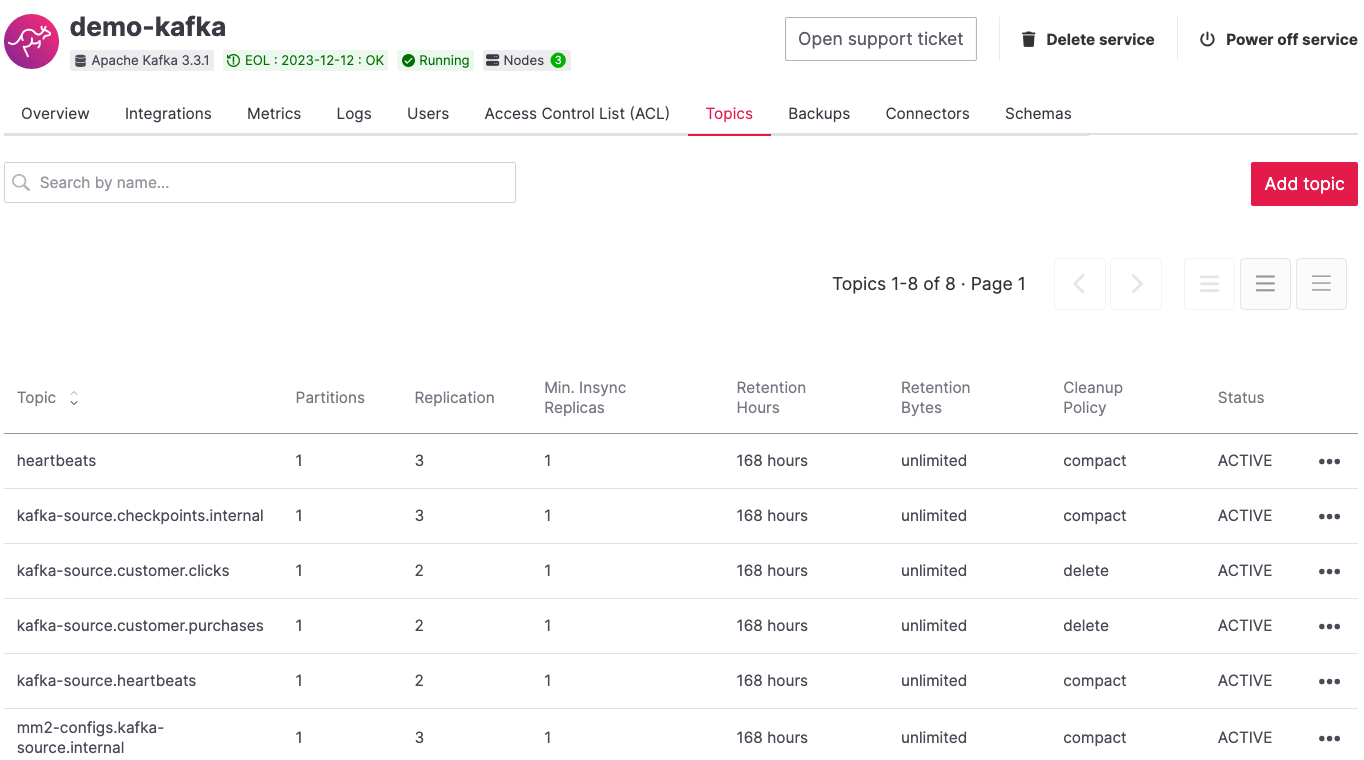
Note
Once you start the replication flow, MirrorMaker 2 continuously checks for topics matching the regular expression defined. If you create new topics matching the regex in the source cluster, they'll appear also in the target cluster.Monitor the MirrorMaker 2 replication flow lag
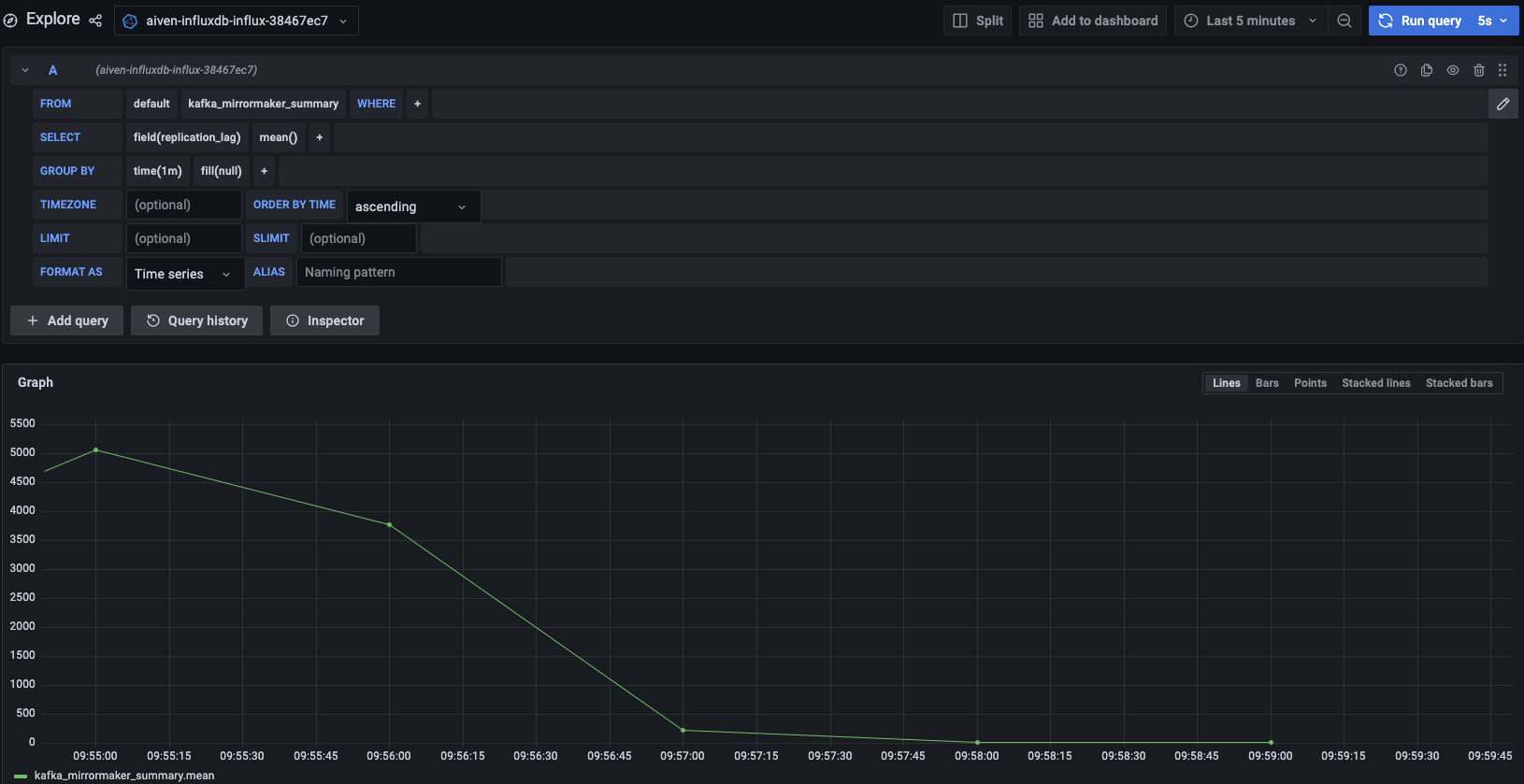
After starting the replication flow, MirrorMaker 2 starts moving data between the source and target Kafka clusters in asynchronous mode. To measure how the replication is performing you might want to check the replication lag: the delay in synchronization between the source and target Apache Kafka cluster. Once the lag is 0, the two Apache Kafka clusters are in sync.
Follow the documentation to review how to create services integrations.
The metric you want to track is called kafka_mirrormaker_summary.replication_lag. The image below showcases a Grafana® dashboard showing the mean MirrorMaker 2 replication lag trending to 0.
Migrate topic schemas
Apache Kafka topic schemas define the structure of the data in certain topics. They can be migrated two different ways:
- By replicating the schemas topic stored in Apache Kafka (usually located in the
_schemastopic). - By extracting the schema information from the source and registering in the target environment using the appropriate APIs.
The second option offers much more control over which schemas are migrated. To register the schemas in an Aiven for Apache Kafka service you can:
- Navigate in the Aiven Console, service page, Schemas tab.
- Use the Karapace rest APIs.
- Use Aiven command line interface.
Migrate access control list
Apache Kafka Access Control Lists (ACLs) define how various users are allowed to interact with the topics and schemas. To migrate ACLs, we recommend extracting the ACL definition from the source Apache Kafka cluster, then recreating the ACL in the target cluster.
If the target of the migration is Aiven for Apache Kafka, you can define the ACLs with:
- The Aiven Console, service page, Access Control Lists (ACL) tab.
- The dedicated Aiven REST API.
- The dedicated Aiven CLI command.
Change client settings
After the replication flow is running and the schemas and ACLs are in place, you can start pointing producers and consumers to the target Apache Kafka cluster.
Warning
To avoid losing Apache Kafka messages during the asynchronous MirrorMaker 2 migration, we suggest stopping the producers, checking that both the consumer lag in the source system and the MirrorMaker 2 replication lag is0, and then pointing producers and consumers to the target Apache Kafka cluster. The migration process provides a detailed series of steps to follow.If the target of the migration is Aiven for Apache Kafka, follow the documentation to download the required certificates and connect as a producer or consumer.
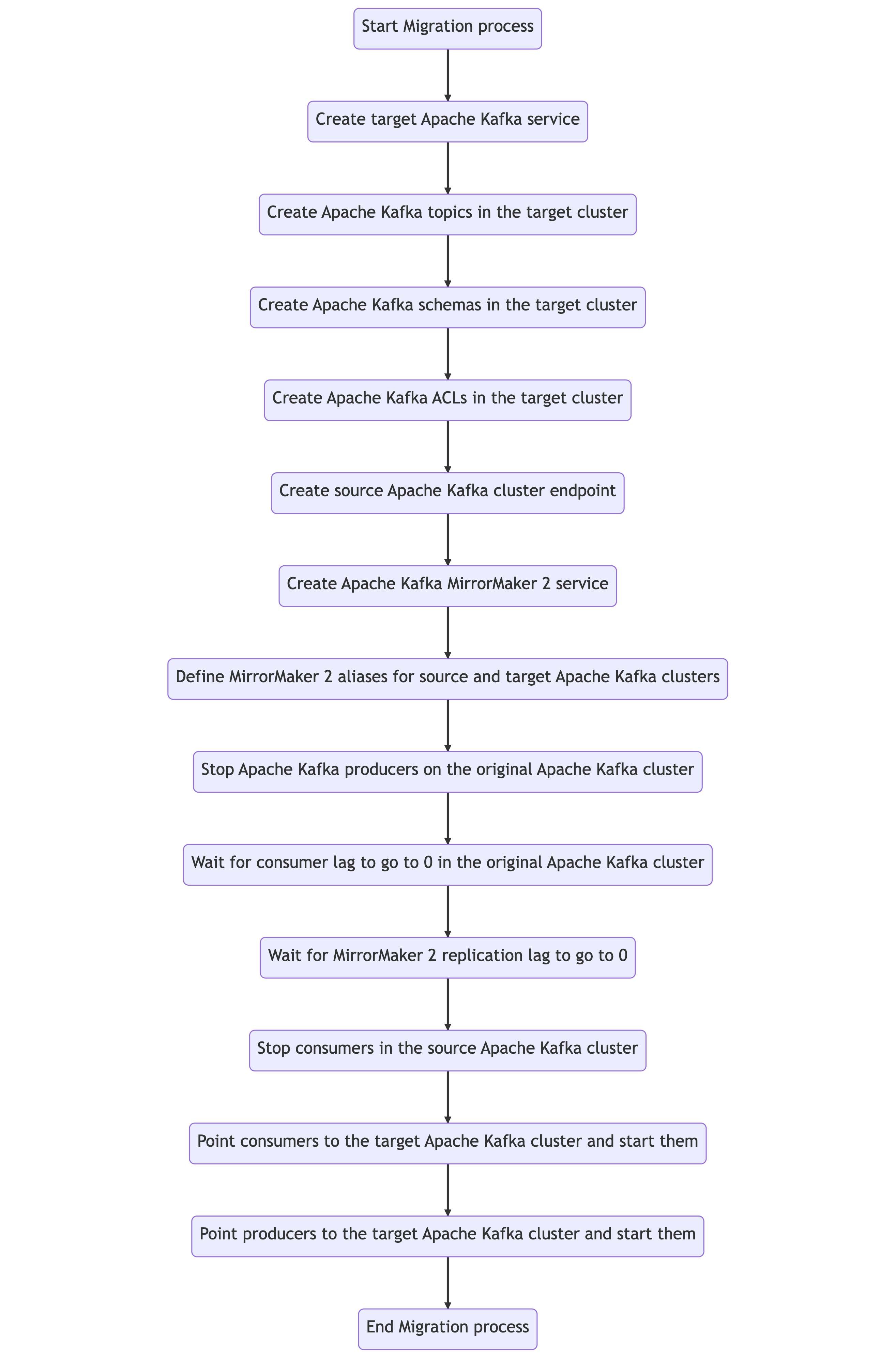
Complete migration process
The following diagram showcases all the steps included in an Apache Kafka migration process.
Check the migration results
When the migration process terminates, check the target Apache cluster to ensure that:
- All the ACLs are in place: in the Aiven Console service page -> Access Control List (ACL) Tab.
- All the schemas are present in the target schema registry (Karapace for Aiven for Apache Kafka): in the Aiven Console service page -> Schemas Tab.
- All the topics included in the replication flows defined are present, and the data is flowing: in the Aiven Console service page -> Topics Tab.
- All the producers and consumers are pointing to the target cluster and correctly pushing/consuming data
Next steps
This guide doesn't cover how to confingure your client data producers and consumers to Aiven for Apache Kafka. The migration is not complete without redirecting data to the new Apache Kafka cluster.
- Learn how to connect to an Aiven for Apache Kafka cluster using a number of different languages
- Test your Aiven for Apache Kafka cluster using the Aiven fake data producer
In this guide we used Aiven's ability to directly spin up and connect to a MirrorMaker 2 instance to create a replication flow and migrate our data. Aiven can also connect directly to a growing number of other services you might find useful, like databases for storing data coming through Kafka, Grafana for metrics, Datadog for observability, and more.
- Learn more about the Aiven data platform and other services you can spin up with your Aiven account
- Or about external services you can integrate with Aiven